AI News
From Contradictions to Coherence: Logical Alignment in AI Models
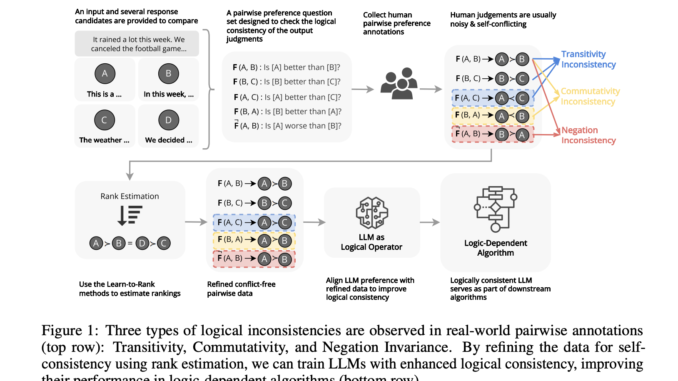
Large Language Models (LLMs) aim to align with human preferences, ensuring reliable and trustworthy decision-making. However, these models acquire biases, logical leaps, and hallucinations, rendering them invalid and harmless for critical tasks involving logical thinking. […]