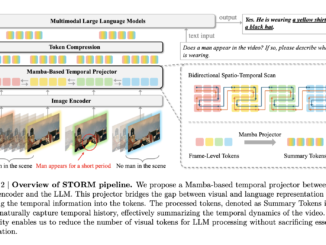
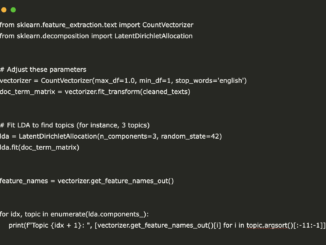
AI News
A Coding Guide to Build a Multimodal Image Captioning App Using Salesforce BLIP Model, Streamlit, Ngrok, and Hugging Face
In this tutorial, we’ll learn how to build an interactive multimodal image-captioning application using Google’s Colab platform, Salesforce’s powerful BLIP model, and Streamlit for an intuitive web interface. Multimodal models, which combine image and text […]