AI News
Optimizing Training Data Allocation Between Supervised and Preference Finetuning in Large Language Models
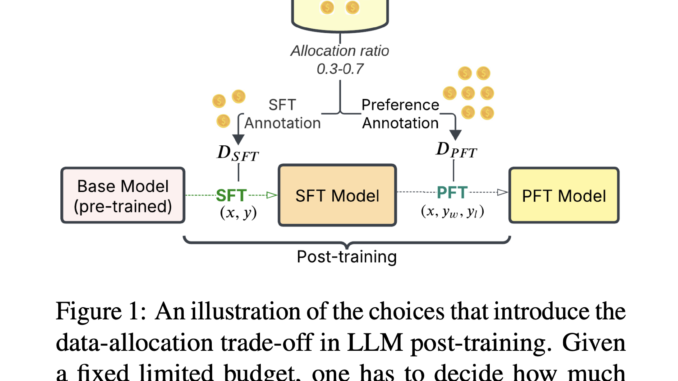
Large Language Models (LLMs) face significant challenges in optimizing their post-training methods, particularly in balancing Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) approaches. While SFT uses direct instruction-response pairs and RL methods like RLHF use […]








